Autonomous Defense Without Autonomous Risk: A Blueprint for Policy-Governed Security Agents
Autonomous defense should not mean letting an AI agent freely fix production. It means a policy-governed system that detects risk, reasons about impact, proposes remediation, executes only low-risk actions, and escalates everything else with full auditability.
Everyone in security is talking about using AI to defend systems. Fewer people are talking about what happens when the AI gets it wrong.
I’ve spent a lot of time thinking about this. Not the detection side. Tooling there has improved dramatically. The harder problem is what comes after detection: safe, verified, auditable remediation at scale. That’s the gap I want to explore here.
The real problem isn’t detection
Security teams today are not short on signals. Cloud posture drift, exposed secrets, risky IAM policies, container findings, Kubernetes misconfigurations, it all gets surfaced. The problem is that surfacing a finding and safely fixing it are completely different problems.
The question that never gets answered fast enough is:
“What is risky, why does it matter, what should be fixed first, and what can be safely remediated without creating new risk?”
That gap between finding and fix is currently filled by humans doing repetitive triage work. An autonomous defensive system should close that gap, but only where it can do so safely. That last part is what most designs get wrong.
The architecture I’d build
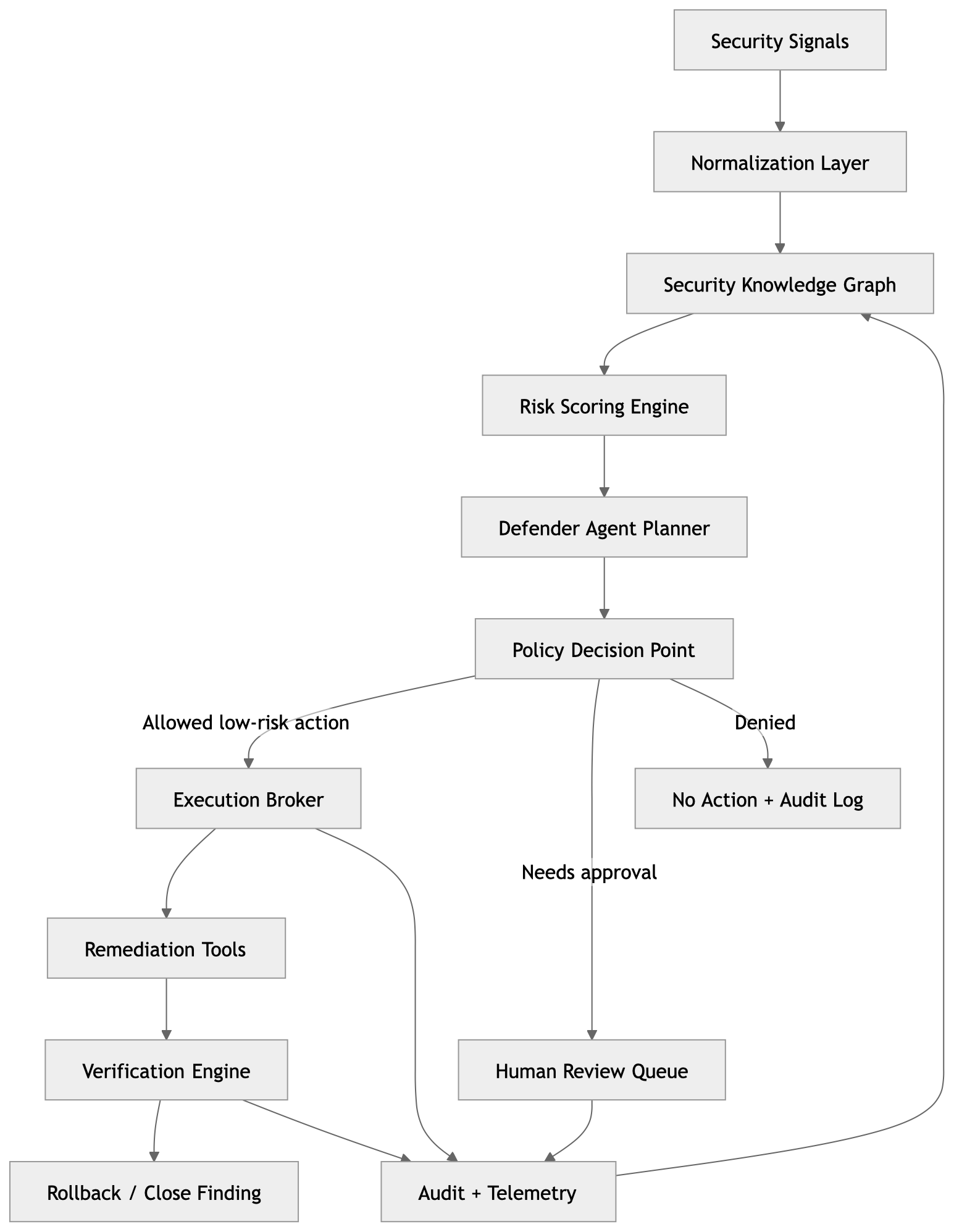
The key design principle: each component does one thing. The agent plans. The policy engine decides. The broker executes. Nothing short-circuits this chain.
1. Signal ingestion and normalization
The system needs to pull from a lot of sources:
- Cloud posture tools (Security Hub, Security Command Center, Defender for Cloud)
- SAST/DAST/SCA scanners
- Kubernetes admission logs and runtime alerts
- IAM analyzer findings
- Asset inventory and ownership metadata
- CI/CD pipeline metadata
- Vulnerability databases (NVD, OSV, GitHub Advisory)
Before anything else happens, everything gets normalized to a common schema:
{
"asset": "payments-api-prod",
"finding": "public_s3_bucket",
"severity": "high",
"owner": "payments-platform",
"environment": "prod",
"data_classification": "restricted",
"internet_exposed": true,
"exploitability": "medium"
}
This feels like boring plumbing work, and it is. But it’s also where most real implementations break down. If downstream components have to handle provider-specific formats, everything becomes fragile and hard to test.
2. Context is everything: the security knowledge graph
Here’s something I feel strongly about: findings should never be evaluated in isolation.
A public S3 bucket is not the same as a public S3 bucket containing restricted payment data reachable from an internet-facing production service. Same finding type, completely different risk. A flat scanner output will treat them identically. A knowledge graph won’t.
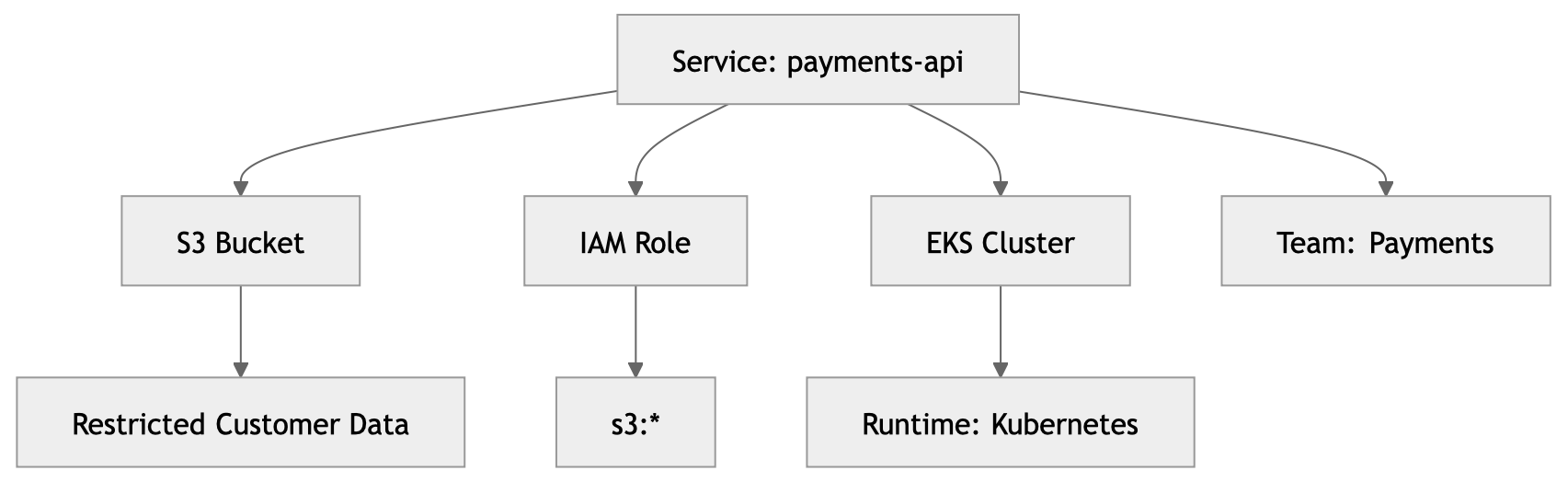
With this graph, the risk engine can reason like this:
“This S3 bucket is public. It’s connected to a production payment service, contains restricted data, and is reachable from an internet-facing workload. The blast radius of exploitation is the entire payments dataset. Treat this as critical.”
Without the graph, you get a severity label. With it, you get context-aware prioritization. That’s the difference between a tool and a system that actually helps.
3. Risk scoring that’s actually explainable
Raw scanner severity is a starting point, not a risk score. A high-severity finding in a dev account with no data and no production traffic is not the same priority as a medium-severity finding in a production service handling customer PII.
I like this model because every score is explainable:
Risk = Severity × Exposure × Asset Criticality × Data Sensitivity × Exploitability × Blast Radius
def calculate_risk(finding):
score = 0
score += finding.severity_score * 0.25
score += finding.exposure_score * 0.20
score += finding.asset_criticality * 0.20
score += finding.data_sensitivity * 0.15
score += finding.exploitability * 0.10
score += finding.blast_radius * 0.10
return round(score, 2)
The weights should be calibrated to your environment. The right calibration for a payments platform is different from an internal tooling team. What matters is that you can always show which inputs drove a score and why. That’s what makes it trustable.
4. The agent plans. It doesn’t act.
This is probably the most important design decision in the whole system.
The agent’s job is to reason about a finding and produce a remediation plan. Nothing more. It doesn’t decide whether it can execute. It doesn’t hold credentials. It just says: “here’s what I think should happen.”
{
"finding": "public_s3_bucket",
"recommended_action": "block_public_access",
"risk": "high",
"confidence": "high",
"requires_human_approval": false,
"rollback_plan": "restore previous bucket policy",
"verification": "confirm public access block is enabled"
}
What happens next is entirely determined by the policy engine. That separation is the core safety property of the system.
5. The policy engine is the safety boundary
This is the component I care about most. Every remediation plan flows through here before anything touches infrastructure.
The policy engine is the safety boundary between AI reasoning and production action.
The engine evaluates the proposed action against explicit, version-controlled rules and returns one of three decisions: allow, require approval, or deny.
package autonomous_defense
default allow = false
allow {
input.action == "block_public_s3_access"
input.environment != "prod"
input.confidence == "high"
input.rollback_available == true
}
allow {
input.action == "rotate_low_privilege_secret"
input.secret_scope == "single_service"
input.owner_notified == true
input.rollback_available == true
}
requires_approval {
input.environment == "prod"
}
requires_approval {
input.action == "delete_resource"
}
deny {
input.blast_radius == "high"
}
A few things I’ve encoded deliberately here:
- Environment matters. Non-prod actions can be automated. Prod requires approval or is denied outright.
- Rollback is a precondition, not an afterthought. No rollback plan, no action.
- Blast radius is a hard gate. High blast radius is always denied, no exceptions.
- Policy is code. It lives in version control, gets reviewed like any other change, and the version is logged with every decision.
Your security posture should live in executable rules, not in a document that nobody reads.
6. Credentials should be narrow and short-lived
Most autonomous system designs fail here. The agent gets an admin service account “for convenience” and the policy layer becomes the only line of defense. That’s not a system, it’s a ticking clock.
The execution broker should only ever hold credentials for the specific action it’s executing, and those credentials should disappear when the action completes.
❌ Agent has admin access to cloud accounts.
Agent decides what to do.
Agent executes.
Log: "agent did something."
✓ Agent produces a plan.
Policy engine approves specific action.
Broker receives narrowly-scoped credential for that action.
Action is executed, logged, and verified.
Log: full context, agent, tenant, action, resource, policy version, outcome.
The bad design has one defense layer. The good design has four.
7. Not everything should be automated
I want to be direct about this because it’s easy to get wrong.
| Action | Automation level |
|---|---|
| Add missing security label | Fully automated |
| Open ticket with fix recommendation | Fully automated |
| Block public access on non-prod bucket | Automated with verification |
| Rotate low-risk secret | Automated with owner notification |
| Change production IAM policy | Human approval required |
| Delete production resource | Denied by default |
| Modify network path or firewall in prod | Human approval required |
The system should be autonomous where blast radius is low, and human-governed where blast radius is high. A human approval gate is not a design failure. It’s the right answer when the cost of getting it wrong is high.
8. Every action needs a closed loop
Executing a fix and assuming it worked is not verification. The system needs to confirm the action had the intended effect and roll back if it didn’t.
Some examples of what verification actually looks like in practice:
- Public access block: confirm the S3 block-public-access flag is enabled
- IAM permission removal: confirm the permission is absent from the current policy
- Package upgrade: confirm the deployed version doesn’t match the vulnerable range
- Kubernetes runtime class: confirm the workload spec references an approved runtime class
- Network egress policy: confirm the policy rejects requests to the instance metadata IP
If verification fails, rollback is automatic and the finding re-enters the queue.
Don’t forget to threat-model the system itself
Any system that can make automated changes to infrastructure is itself a high-value target. A few things worth thinking through:
Prompt injection via finding content. An attacker controls a resource name or tag that gets embedded in the agent’s context and manipulates it into proposing the wrong action. Treat all external data as untrusted.
Policy bypass via crafted input. A finding or plan constructed to satisfy policy conditions it shouldn’t. Policy evaluation should use data from authoritative sources, not data passed in by the agent.
Credential theft from the broker. Credentials should be requested per-action and invalidated immediately after use. No persistent credential store.
Audit log tampering. If the agent can modify its own audit log, you’ve lost the trail. Write to an append-only, externally controlled sink.
The point
The opportunity isn’t in building an AI that can fix infrastructure. That’s the easy part. The hard part is building a system that governs the AI’s ability to act, with explicit policy, least-privilege execution, verification, rollback, and a complete audit trail.
An AI that can fix production only when policy allows, only with minimum required permissions, only with a verified rollback path, and only while writing every decision to an immutable log. That’s a system security teams can actually trust.
I’ve built a working demo of this: autonomous-defense-policy-agent. It runs against simulated findings and shows exactly how each component behaves across allow, approval, and deny paths.